Convert JSON to Parquet files on Google Cloud Storage using BigQuery

Do you have lots of files on Google Cloud Storage that you want to convert to a different format?
There are a few ways you can achieve it:
- Download the files to a VM or local machine, then write a script to convert them
- Use services like Cloud Function, Cloud Run or Cloud Dataflow to read and write the files on Cloud Storage
But what if there is a true serverless way? And you only need to write SQL to convert them?
Let me walk you through it.
Prepare the source data
I wrote a Python script to generate a gzipped JSONL file.
import gzip
import json
def main():
json_str = ''
for i in range(10):
json_str = json_str + json.dumps(dict(id=i, value=i * i)) + "\n"
json_bytes = json_str.encode("utf-8")
with gzip.open("test.jsonl.gz", "w") as fout:
fout.write(json_bytes)
if __name__ == "__main__":
main()
Uploaded it to my GCS bucket and read it
By following the Google document about BigQuery external table, I was able to query it:
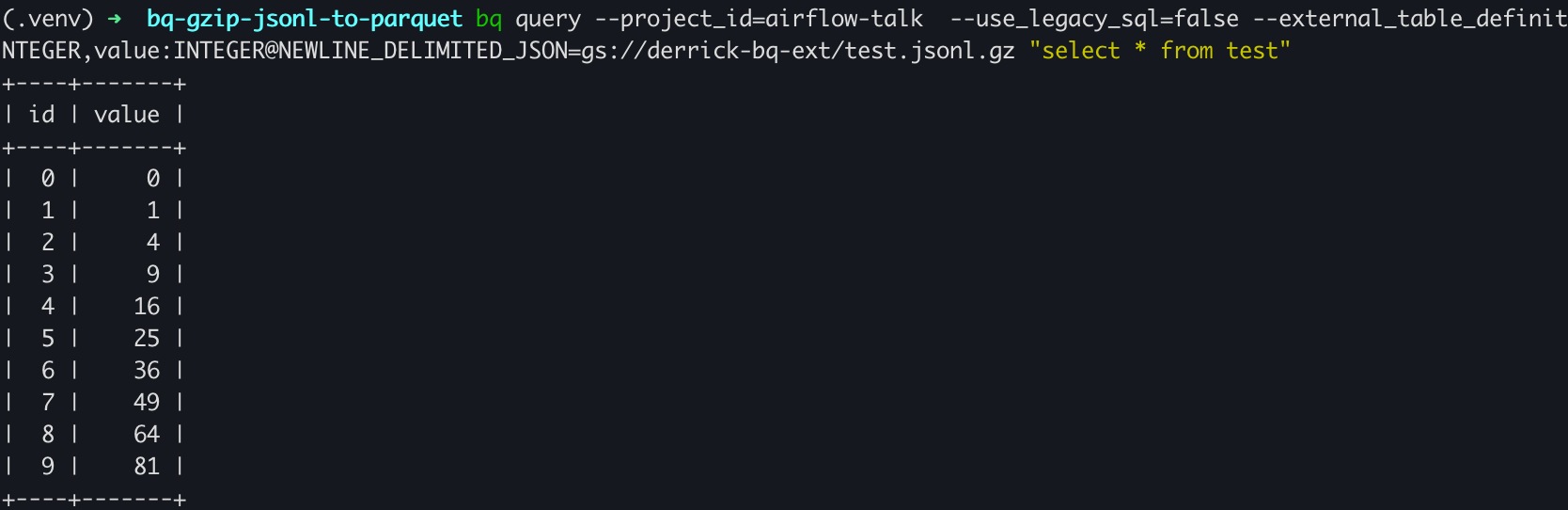
Time to convert it to Parquet format
To achieve this, I used BigQuery EXPORT DATA statement to "export" the data from BigQuery to Cloud Storage in PARQUET format:

After navigating to the Cloud Storage console, I can see the PARQUET file:
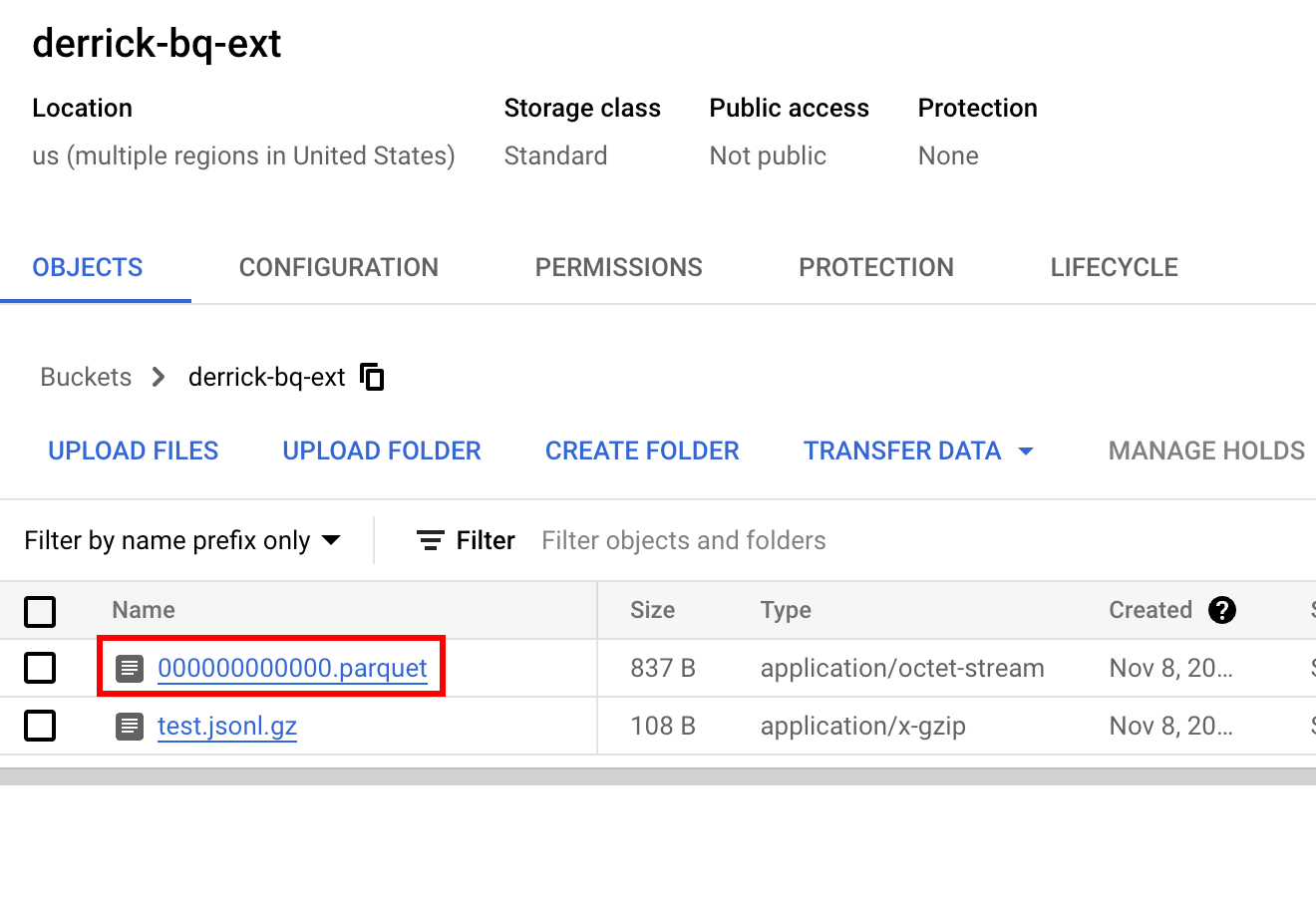
Verify the data
Finally, I'd like to verify the data is actually in the PARQUET file:
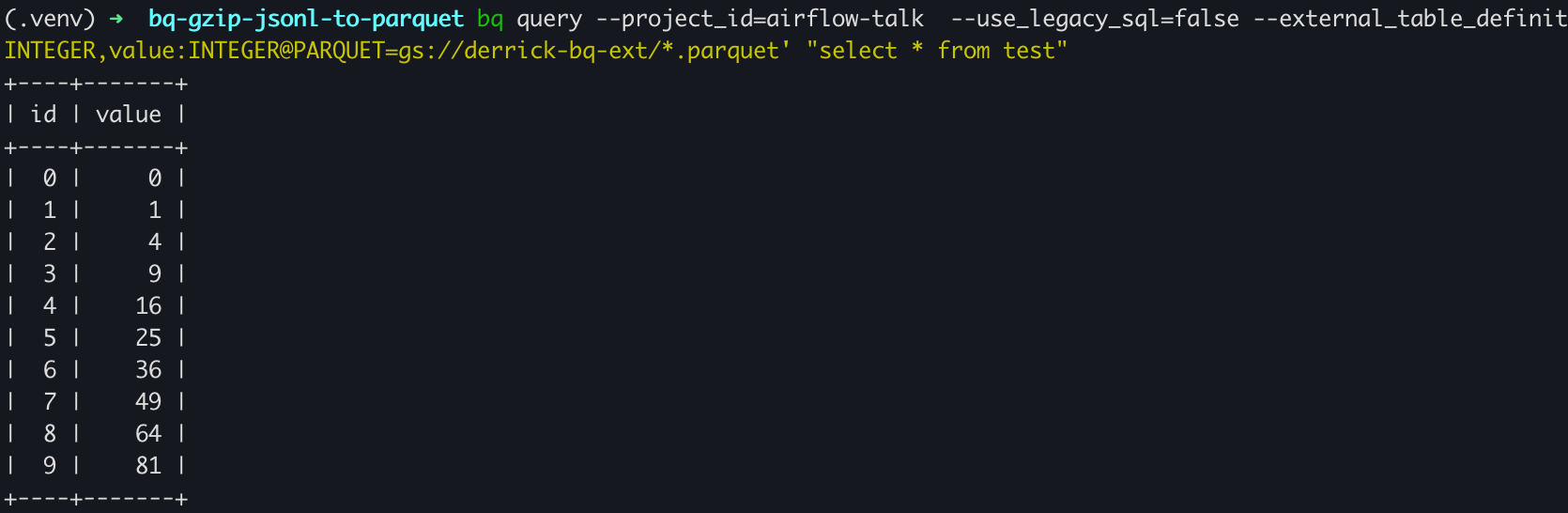
And yay!
Summary
Using BigQuery's native EXPORT DATA statement, I was able to convert gzipped JSONL files on Google Cloud Storage to PARQUET format.
You can also convert the files to other formats. It currently supports AVRO, CSV, JSON and PARQUET. It is straightforward and serverless.